A real-time audio visualization project featuring a full GUI control panel and a preset system, with support for local audio uploads and system audio input. Demo video:
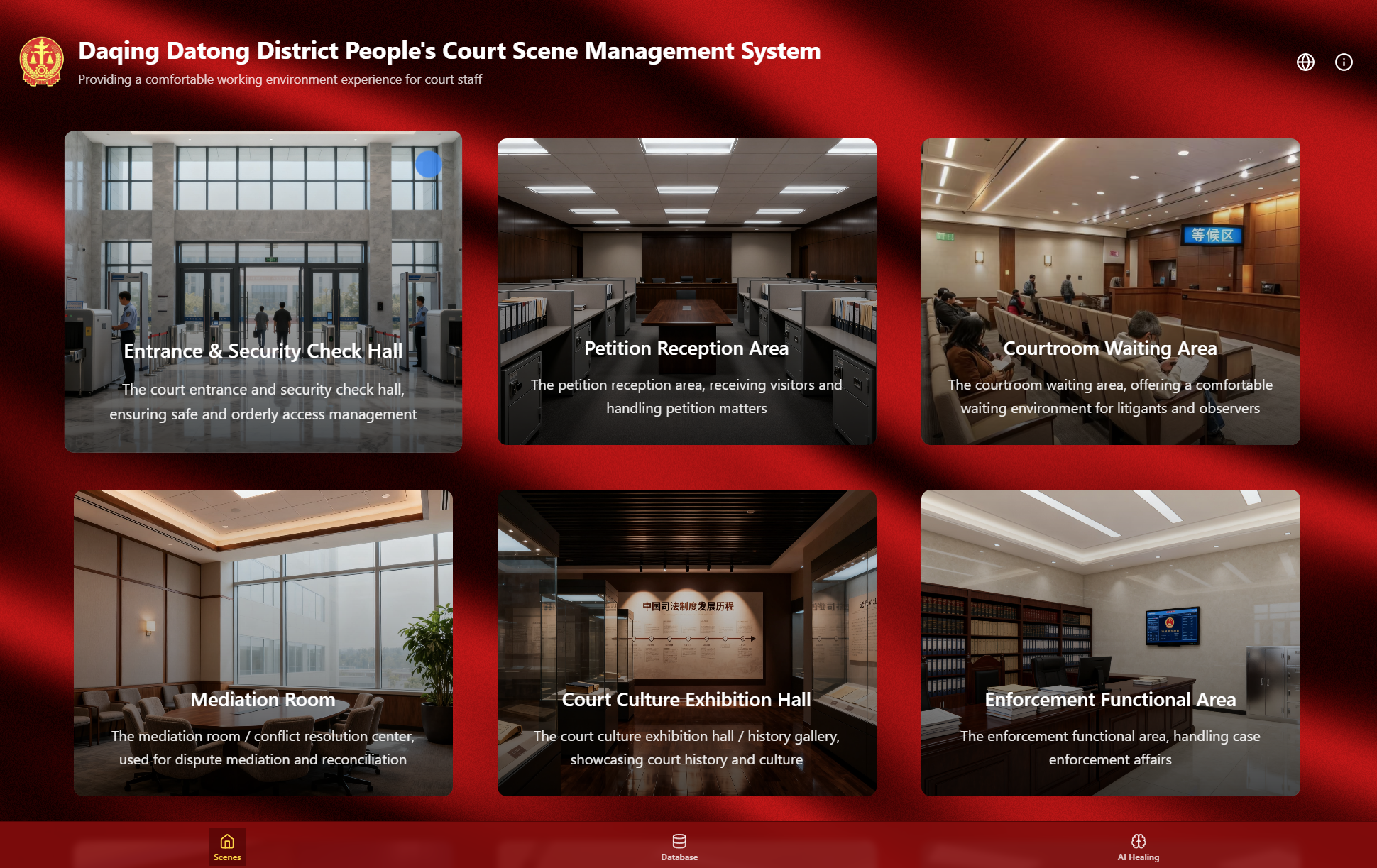
Built a real-time multimodal digital human for dialogue and music using full-stack development. The system ingests text, audio and video in real time, uses face recognition to personalize responses and manage attention, and matches lip and facial movements to generated speech. The music agent tracks emotional state from voice and image, logs these states for experiments, and queries a backend database to select tracks that match the user's emotion and request. Implemented the web frontend in JavaScript, and the system is now in production at a provincial court.